Go to App
Go to App Subscribe
Subscribe


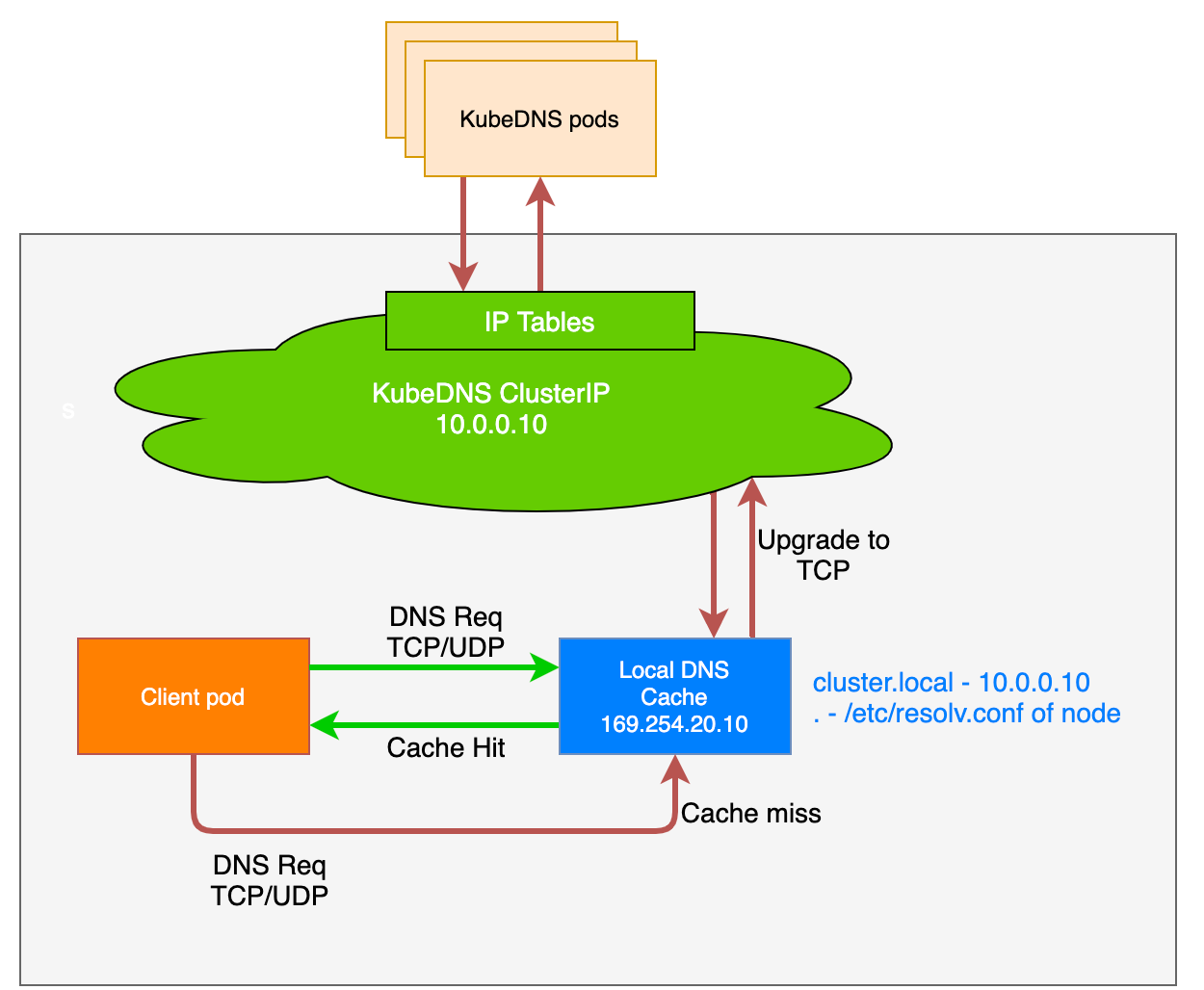
Recently we started seeing a bunch of DNS lookup timeouts in our Kubernetes cluster. Every pod has the name server. All the DNS lookups from that pod is going through the name server only.
How DNS lookups works
In our case nameserver 172.20.0.10 , which is a ClusterIP of kube-dns .

So a DNS lookup request from a pod is going to be sent to 172.20.0.10 and from there it reaches the DNS server . It is done by DNAT and the mechanism is also known as conntrack. The main responsibility of DNAT is to forward the request from kube-dns service chain to the requested DNS server.
conntrack is implemented as a kernel module and a core feature of kernel networking stack. DNS lookup timeouts is mostly due to races in conntrack and the issue is Kernel specific, not Kubernetes.

{kind=link}
Problem and scaling CoreDNS
We used to get intermittently DNS failures. Initially we thought that it could be because of CoreDNS scalability issue. So, we increased the resources of CoreDNS and ran it as a DaemonSet in each Node. We recently migrated from GCP to AWS and it was very new to us. As time passed by, it became more frequent. Not only external DNS failures, but inter pod communication was breaking as well. CoreDNS was getting flooded with "timed out" errors and pods were not be able to communicate internally. It used to get resolved temporary if we restart the CoreDNS pods. We also setup a CronJob to restart the CoreDNS pods periodically.
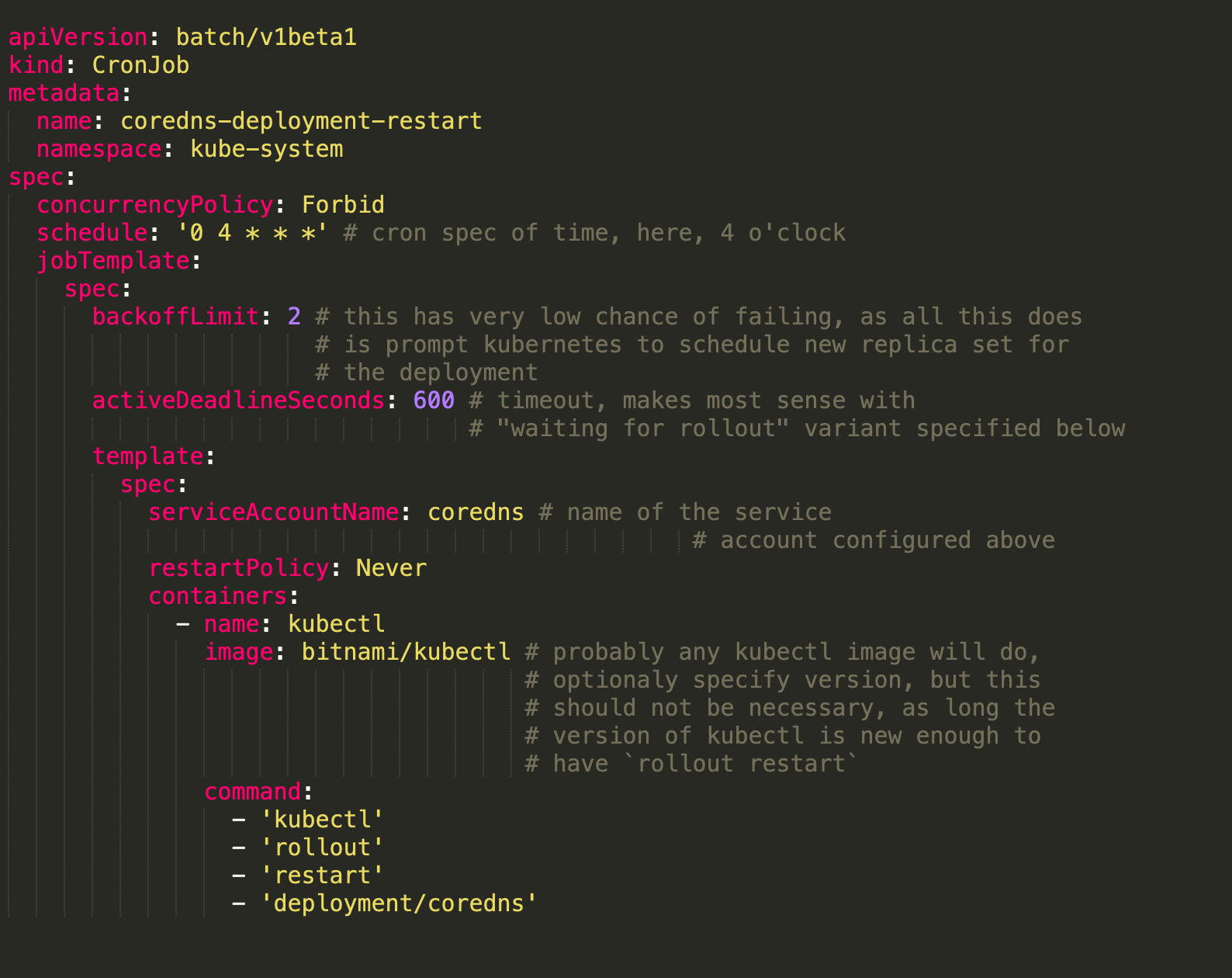
We also made sure that we receive the alerts of CoreDNS error logs. Application logs are getting stored into Elasticsearch and we have slack web hook integration enabled. But, you can not monitor a system all the time and human errors are not avoidable. We also wanted to make sure that we fix it permanently. Then we came across a Github issue regarding conntrack race conditions. Finally, this is what we were looking for.

Upgrading the cluster
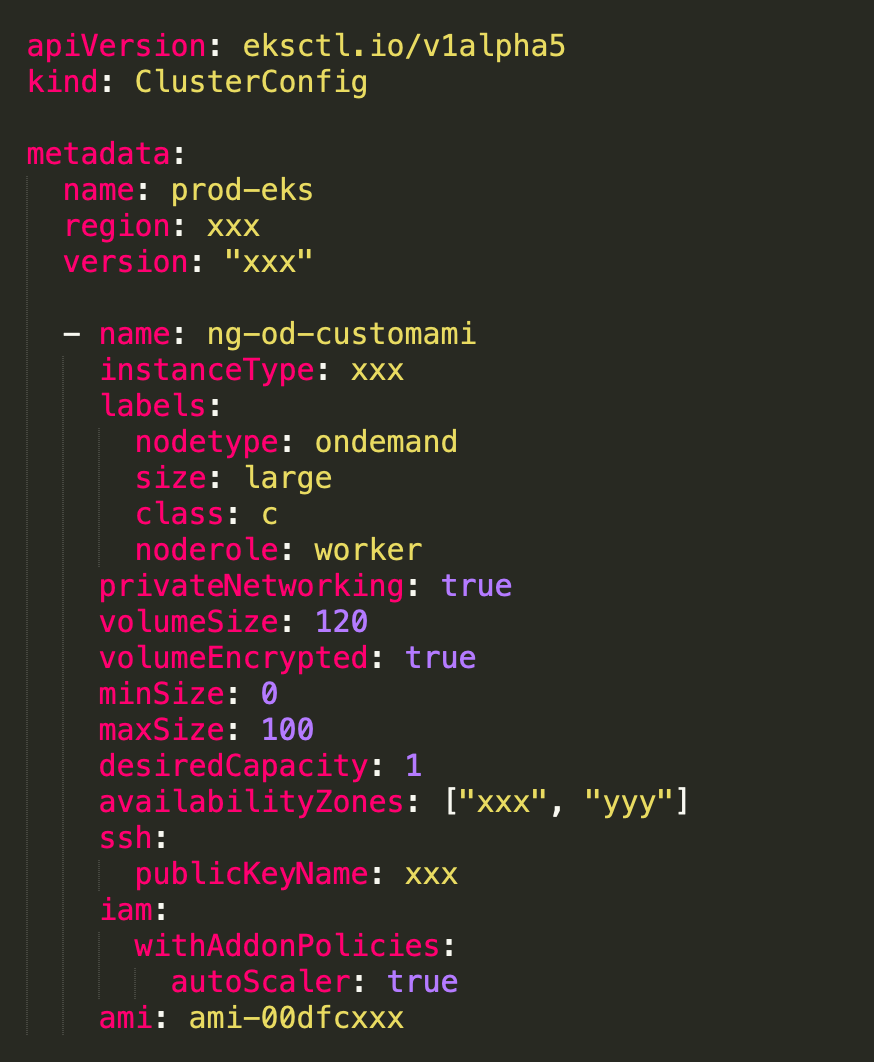
We are using EKS cluster and kernel version was below 5.1 . One option was to upgrade the Kubernetes cluster but we had to resolve it without interrupting the running services in Production. We decided to build a custom AMI with upgraded kernel and then create a NodeGroup to schedule the pods. Initially we made sure that at least CoreDNS pods were scheduled to the new NodeGroup.
Enabling NodeLocal DNS Cache
It resolved most of the timeouts. As an addition we also implemented NodeLocal DNSCache . It runs DNS Caching agents on nodes as a Daemonset and improves the Cluster DNS performance. Combination of both helped us to resolve 95% of timeouts issues. It works as a CoreDNS caching agent running on same node. It helps to avoid connection tracking and iptables DNAT rules.